◆PROCESSING 逆引きリファレンス
 カテゴリー:ファイル操作
カテゴリー:ファイル操作
ZIP解凍を行うには(標準ライブラリ編)
【概要】
PROCESSINGはJavaをベースにした言語ですので、Javaの機能を利用してZIPファイルの解凍を行うことが可能です。
ただしJavaの標準機能(標準ライブラリ)では、パスワード付きのZIPファイルを解凍することができません。
パスワード付きのZIPファイルを解凍したい場合は、標準ライブラリではなく、zip4j ライブラリを利用するのが良いでしょう。
zip4jを用いた解凍方法については「ZIP解凍を行うには(zip4j編)」記事を参照してください。
またZIPファイルの解凍に際してはセキュリティを考慮する必要があります。安易に解凍処理を作成すると、思わゆセキュリティ事故につながる事があるので注意してください。
詳しくは下記サイト様の記事を参照してください。本記事でも下記サイト様の記事を元に説明を行います。
【詳細】
ZIP解凍を行うには
- 圧縮されたファイルを元に、ZipInputStreamを作成
- ZipInputStreamから、ZipEntryを取得
- チェックしながら解凍
- ZipEntryとZipInputStreamをcloseする
という手順で処理を行います。
以下、順番に説明をします。
ZipInputStreamを作成
ZipInputStreamは、ZIPファイルの解凍を行う基本となるクラスです。圧縮ファイル名を元にFileInputStreamを作成し、それを与えることでインスタンスを作成します。
ZipInputStream zis = new ZipInputStream(InputStream is, Charset charset);
zis:作成したZipInputStreamインスタンス
is:入力対象となるファイルストリーム
charset:エントリ名とコマンドに使用する文字コード
ポイントは文字コードの指定です。
圧縮ファイルが(日本版)Windowsで作られたものなら、文字コードに「Shift_JIS」または「MS932(windows-31j)」が使われている確率が高いです。
なぜなら(日本版)Windowsでは、ZIPファイルに含まれるファイル名やフォルダ名はMS932(windows-31j)である事がデフォルトとなっているからです。
その一方で圧縮ファイルがMacやLinuxで作られたものなら、文字コードに「UTF-8」が使われている可能性があります。
|
1 2 3 4 5 6 7 8 |
//ZIP入力用オブジェクトを生成 try { FileInputStream is = new FileInputStream("c:\\temp\\hoge.zip"); ZipInputStream zis = new ZipInputStream(is, Charset.forName("Shift_JIS")); } catch( FileNotFoundException e){ e.printStackTrace(); } |
例えば上記のようになります。Charsetで指定可能な文字コードについては、公式ドキュメント を参照してください。
ZipEntryを取得
作成したZipInputStreamから、getNextEntry()メソッドで解凍対象となるファイルのエントリー情報を取得します。
エントリーはZipEntryクラスのインスタンスとして取得されます。
ZipEntryを取得ZipEntry entry = zis.getNextEntry();
zis:ZipInputStreamインスタンス
entry:エントリー情報
取得できない場合はIOExceptionかZipExceptionの例外が発生します。エントリーが無い場合はnullが戻されます。
エントリーが取得出来たら、圧縮対象ファイルの中身を読み出します。すべて読みだしたらZipInputStreamのcloseEntry()メソッドでエントリーを閉じます。
一連の流れは以下のようになります。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
//解凍用にエントリー情報を取得する ZipEntry entry = null; try { while ((entry = zis.getNextEntry()) != null) { //FileOutputStreamへ書き込む処理など //エントリーを閉じる zis.closeEntry(); } zis.close(); } catch( IOException e){ e.printStackTrace(); } |
チェックしながら解凍
特に難しいことを考えないのであれば、Entryを開いて、ファイル書き込み用のOutputStreamへZipInputStreamのread()メソッドで得られたデータを順次書き込めば良いことになります。
次のような感じです(注:以下のロジックは流用しないで下さい。脆弱性があるためです)
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
//************************************** //セキュリティ上の問題があるコード例(流用NG) //************************************** ZipEntry entry = null; try { while ((entry = zis.getNextEntry()) != null) { //FileOutputStreamへ書き込む処理 byte data[] = new byte[1024]; // ファイルをディスクに書き出す //以下の処理に脆弱性がある FileOutputStream out = new FileOutputStream(entry.getName()); byte[] buf = new byte[1024]; int size = 0; while ((size = zis.read(buf)) != -1) { out.write(buf, 0, size); } out.flush(); out.close(); zis.closeEntry(); } zis.close(); } catch( IOException e){ e.printStackTrace(); } |
一見問題ないように見えますが、上記のコードには以下のような問題があります。
- entry.getName()の正当性を検査していない
- ファイルサイズの正当性を検査していない
entry.getName()の正当性を検査する
entry.getName()が解凍側の予期しない場所を指していた場合、思わぬ場所にファイルが作成されてしまう可能性があります。
なぜならZIPファイルのエントリーには、ディレクトリパスを含めることができるからです。これを悪用すると、システムの重要なファイルを勝手に書き換えられる攻撃(ディレクトリトラバーサル攻撃)が成立します。
以下はわかりやすいように、試験的に作成したディレクトリパス付きのZIPファイルです。
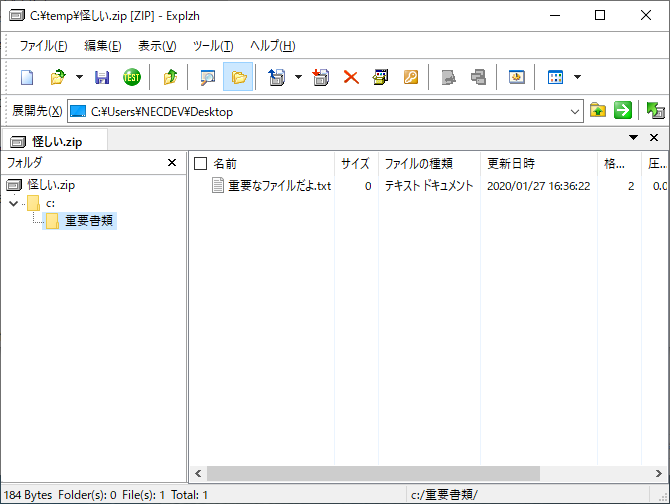
このようなZIPファイルを上記ロジックで解凍すると、例えば「c:\\temp」の下で解凍作業を行ったはずなのに、「c:\\重要書類」というフォルダにある大切なファイル(重要なファイルだよ.txt)が上書き更新されてしまいます(当たり前ですが、決して悪用してはいけません。念のため)。
このような攻撃を防ぐには、今から解凍しようとしているEntry情報のパスが、解凍先のカレントフォルダー配下になっているかどうかを検査します。
あるいはEntry情報のパスがどこであっても、強制的に解凍先のフォルダー配下とみなして解凍するという方法もあります。
今から解凍しようとしているEntry情報のパスが、解凍先のカレントフォルダー配下になっているかどうかを検査するには、下記のようにします(JPCERT コーディネーションセンター 様に掲載されていたものを改編)。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
/** * 解凍元パスの整合性を検査する * @param filename 解凍元ファイル * @param intendedDir 解凍先フォルダ * @throws java.io.IOException 解凍元が想定外の場所の時 * @see JPCERT(https://www.jpcert.or.jp/java-rules/ids04-j.html) */ private void validateFilename(String filename, String intendedDir) throws java.io.IOException { //解凍元の絶対パスを得る(例:C:\重要書類\重要なファイルだよ.txt) File f = new File(filename); String canonicalPath = f.getCanonicalPath(); //解凍先の絶対パスを得る(例:D:\Temp) File iD = new File(intendedDir); String canonicalID = iD.getCanonicalPath(); //解凍元のパスの始まりが、解凍先のパスであるか検査する if (canonicalPath.startsWith(canonicalID)) { //OK return ; } else { //NG throw new IllegalStateException( "File is outside extraction target directory."); } } |
これを
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
//解凍用にエントリー情報を取得する ZipEntry entry = null; try { //解凍する while ((entry = zis.getNextEntry()) != null) { //解凍元パスが正しいか検査する(異常なら例外) validateFilename(entry.getName(), "."); //解凍処理 zis.closeEntry(); } } catch( IOException e){ //例外処理 } |
のように呼び出します。
こうする事でディレクトリパス付きのZIPファイルが、意図しない場所に解凍される事を防止できます。
ファイルサイズの正当性を検査する
もう1つの問題は、対象ZIPファイルにあるファイルのサイズについてです。異常に大きなファイルが圧縮されていると、解凍した際にDISKやメモリ容量を大量に消費してしまいます。もちろんCPUも大忙しになりますね(汗)。
またZIPファイルでは、ZIPファイルの中に複数のZIPファイルを入れ子状態で格納する事が可能です。
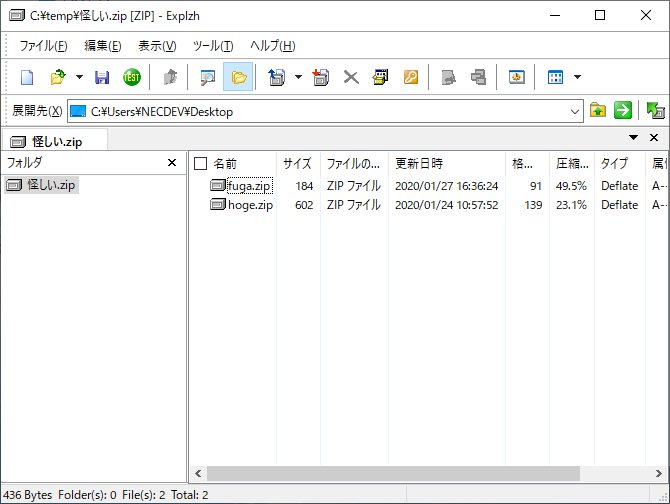
例えば上記では、「怪しい.zip」ファイルの中に2つのZIPファイルが含まれています。
これ自体は問題ないのですが、これを悪用するとZIP爆弾と呼ばれる攻撃が成立してしまいます。具体的には大量のZIPファイルを入れ子状態に圧縮する事で、解凍するコンピュータ側を動作不能に陥らせる攻撃です(こちらも、決して悪用してはいけません)。
このような攻撃を防止するためには、ZIP解凍するファイルサイズを実際に解凍しながら検査し、一定以上のサイズになったら解凍を中止する事です。
ZIPファイルの展開後のサイズは、ZipEntryのgetSize()メソッドで得ることが可能です。が・・・このサイズは信用してはいけません(泣)。
もちろん正常なZIPファイルであれば信用してよいのですが、悪意のあるZIPファイルの場合は、展開後のサイズを詐称する事が可能だからです。ですので処理時間はかかってしまいますが、少しずつ解凍しながら検査を行います。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 |
//解凍用にエントリー情報を取得する //@see JPCERT(https://www.jpcert.or.jp/java-rules/ids04-j.html) final int TOTAL_SIZE = 10240; //このサイズを超えたら異常 boolean breakFlg = false; //中断FLG ZipEntry entry = null; try { int totalSize = 0; while ((entry = zis.getNextEntry()) != null && breakFlg == false) { //解凍元パスが正しいか検査する(異常なら例外) validateFilename(entry.getName(), "."); //FileOutputStreamへ書き込む処理 byte data[] = new byte[1024]; // ファイルをディスクに書き出す FileOutputStream out = new FileOutputStream(entry.getName()); byte[] buf = new byte[1024]; int size = 0; //最大1024バイトずつ展開する while ((size = zis.read(buf, 0, 1024)) != -1) { //TOTAL_SIZE以上になったら、そこで中断 totalSize = totalSize + size; if( totalSize >= TOTAL_SIZE){ //上限を超えたので中止 println("uncompress file size limit over."); breakFlg = true; break; } //書き込む out.write(buf, 0, size); println( size + "byte write.total size=" + totalSize ); } out.flush(); out.close(); if(breakFlg){ //MAXオーバーなら、該当ファイルを削除する new File(entry.getName()).delete(); } zis.closeEntry(); } zis.close(); } catch( IOException e){ e.printStackTrace(); } |
例えば上記のような感じです。
この例であれば、解凍した複数ファイルの合計が10Kバイトを超えたら、そこで解凍処理が中断されます。
実際のプログラムでは解凍先のディレクトリが存在しない場合も考慮しつつ、処理を記述する必要があります。
【関連記事】
サンプルプログラム
ZIPファイルを解凍する例:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 |
/** * PROCESSING 3 ZIP解凍Sample * @auther MSLABO * @version 2020/01 1.0 * @see JPCERT(https://www.jpcert.or.jp/java-rules/ids04-j.html) */ import java.io.*; import java.nio.charset.Charset; import java.util.zip.ZipEntry; import java.util.zip.ZipInputStream; final int TOTAL_SIZE = 10240; //このサイズ(10K)を超えたら異常 final String targetFile = "c:\\temp\\hoge.zip"; final String destDir = "c:\\temp"; void setup(){ //ZIP入力用オブジェクトを生成 FileInputStream is = null; ZipInputStream zis = null; try { is = new FileInputStream(targetFile); zis = new ZipInputStream(is, Charset.forName("Shift_JIS")); } catch( FileNotFoundException e){ e.printStackTrace(); } //解凍用にエントリー情報を取得する boolean breakFlg = false; //中断FLG ZipEntry entry = null; FileOutputStream out = null; try { int totalSize = 0; while ((entry = zis.getNextEntry()) != null && breakFlg == false) { //解凍元パスが正しいか検査する(異常なら例外) validateFilename(entry.getName(), "."); //解凍先のパスを生成 File outPath = new File(destDir + File.separatorChar + entry.getName()); //フォルダを作成する if( entry.isDirectory() ) { outPath.mkdirs(); continue; } // ファイルをディスクに書き出す byte data[] = new byte[1024]; out = new FileOutputStream(outPath); byte[] buf = new byte[1024]; int size = 0; while ((size = zis.read(buf, 0, 1024)) != -1) { //TOTAL_SIZE以上になったら、そこで中断 totalSize = totalSize + size; if( totalSize >= TOTAL_SIZE){ //上限を超えたので中止 breakFlg = true; break; } //最大1024バイトずつ展開する out.write(buf, 0, size); } out.flush(); out.close(); if(breakFlg){ //MAXオーバーなら、該当ファイルを削除する outPath.delete(); } zis.closeEntry(); } zis.close(); } catch( IOException e){ e.printStackTrace(); } } void draw(){ } /** * 解凍元パスの整合性を検査する * @param filename 解凍元ファイル * @param intendedDir 解凍先フォルダ * @throws java.io.IOException 解凍元が想定外の場所の時 * @see JPCERT(https://www.jpcert.or.jp/java-rules/ids04-j.html) */ private void validateFilename(String filename, String intendedDir) throws java.io.IOException { //解凍元の絶対パスを得る(例:C:\重要書類\重要なファイルだよ.txt) File f = new File(filename); String canonicalPath = f.getCanonicalPath(); //解凍先の絶対パスを得る(例:D:\Temp) File iD = new File(intendedDir); String canonicalID = iD.getCanonicalPath(); //解凍元のパスの始まりが、解凍先のパスであるか検査する if (canonicalPath.startsWith(canonicalID)) { //OK return ; } else { //NG() throw new IllegalStateException( "File is outside extraction target directory."); } } |
上記のサイズチェックと解凍先パスの検査処理は、JPCERT コーディネーションセンター 様に掲載されていたものを改編しています。
本例では、targetFile(”c:\\temp\\hoge.zip”)を destDir(”c:\\temp”)配下に解凍します。解凍するファイルサイズがTOTAL_SIZE(上記では10240=10K)を超えると、解凍できないようにしています。
<出力サンプル>
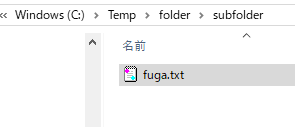
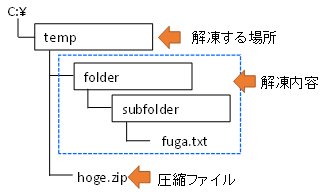
解凍した様子です。下図のような位置関係にあります。
本ページで利用しているアイコン画像は、下記サイト様より拝借しております。各画像の著作権は、それぞれのサイト様および作者にあります。