◆PROCESSING 逆引きリファレンス
 カテゴリー:文字関連処理
カテゴリー:文字関連処理
OCRを実現するには
【概要】
最近のコンピュータは人工知能や機械学習を取り入れて、従来では非常に困難だった自然風景の中から特定の物を見分ける事(例えば人間の顔を認識するなど)が、簡単に行えるようになりました。
顔認証については「顔認証を行うには(OpenCV)」記事で紹介していますので、よろしければ参照してください。
コンピュータが「画像の中から何かを認識する」といえば、古くからOCRが有名です。
OCR(Optical Character Recognition/Reader、光学的文字認識)とは、手書きや印刷された文章をコンピュータに読み込ませ、書かれている文字(文章)を認識する(抜き出す)処理の事です。
デジタル化されていない昔の書物や名刺などの印刷物から、文字情報を読み取り、データベース化する処理などで活用されています。
無償で利用できるOCRライブラリとしては
あたりが有名です。
今回は、その中からTesseract OCRを試してみる事にしました。
Tesseract OCRは元々C++用のライブラリなのですが、これをJavaから利用できるようにしたTess4Jが、以下のサイト様で公開されています。
またAPIについては、下記サイト様にまとめられています。
上記公式サイト様から、以下の手順に従って最新版のライブラリをダウンロードしてインストールする事で、PROCESSINGからTess4Jが利用できるようになります。
なお日本語を認識するには別途言語ファイルが必要となります。
Tess4J で日本語を認識させたい方は、上記リンク(tessdata)から日本語用の言語ファイル「jpn.traineddata」もダウンロードしてください。
最新版のライブラリをダウンロードする
Tess4J公式サイトからライブラリをダウンロードします。

2018/04現在、Tess4J-3.4.7-src.zip がダウンロード可能です。また言語ファイルは、GitHubで公開されています。
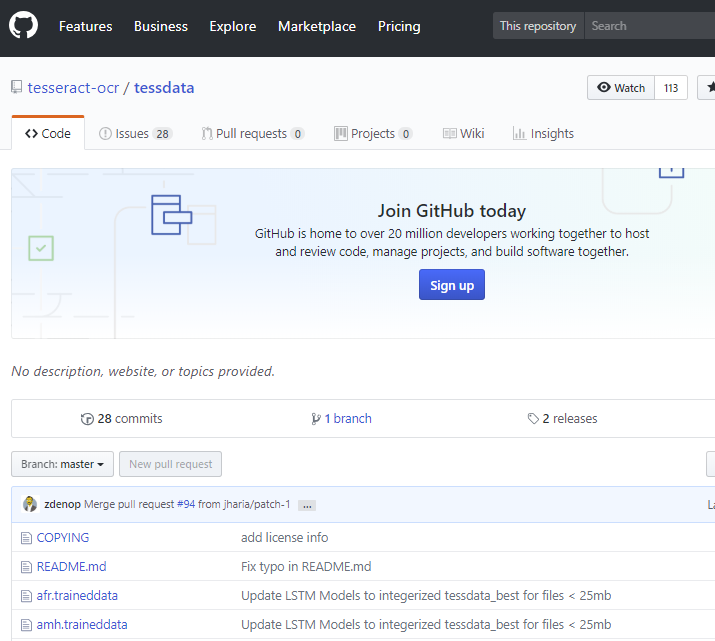
ダウンロードした zip ファイルを適当な場所に解凍してください。以下のようなファイルとフォルダが出来上がるはずです。
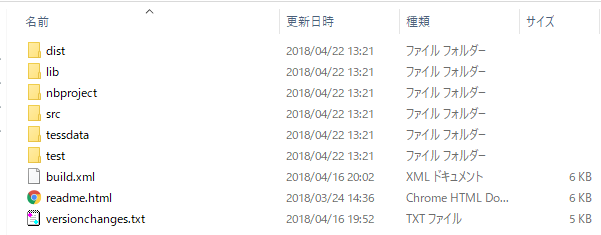
dist 配下には、Java用の Tessライブラリ「tess4j-3.4.7.jar」があります。
lib 配下には沢山の関連ライブラリと、Windows64bit/32bit用の DLL ライブラリが格納されています。
tessdata配下には、ライブラリが動作するために必要な設定ファイルが格納されています。
PROCESSINGで利用できるようにする
まずPROCESSINGの標準エディタから「新規プロジェクト」を作成し、空で良いので一度保存します。
なお保存前に「ファイル→設定」で、スケッチブックの場所に「わかりやすいパス」が指定されている事を確認してください。
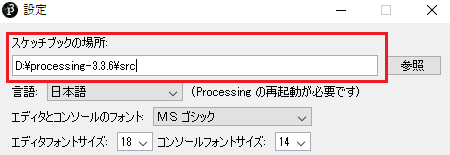
上記例なら、スケッチを保存すると「D:\processing-3.3.6\src」に「sketch_180422a」などのフォルダが作成され、空のプログラムソースファイルができあがります。
このフォルダ(D:\processing-3.3.6\src\sketch_180422a)配下に、Tess4Jを解凍してできた tessdata フォルダを、フォルダごと複写します。
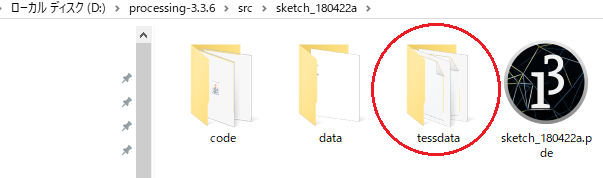
Tess4Jで日本語を認識させたい方は、複写した tessdata フォルダ配下に、別途ダウンロードした日本語言語ファイル「jpn.traineddata」を複写しておきます。
英語しか読み取らない人は、日本語言語ファイル「jpn.traineddata」のダウンロードや複写は不要です。
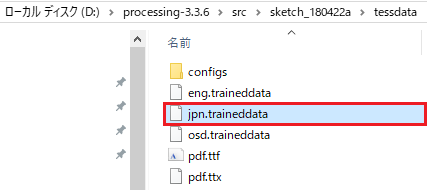
続いて、スケッチ格納フォルダ(D:\processing-3.3.6\src\sketch_180422a)配下に、code フォルダを作成してください。
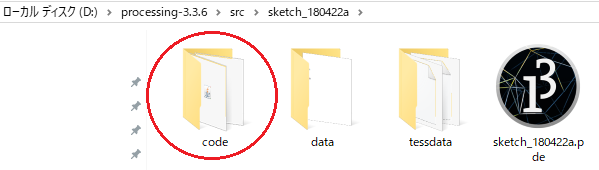
codeフォルダには、Tess4Jを解凍してできたdist と lib フォルダ配下から、以下のファイルを複写しておきます。
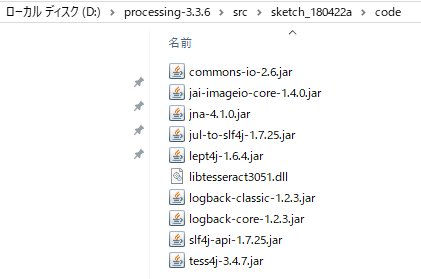
ここでのポイントは、dll に「あなたの環境に適合したもの」を使う事です。
64bit Windows で利用するなら 「Tess4J\lib\win32-x86-64」配下にあるlibtesseract3051.dllを、32bit Windows で利用するなら「Tess4J\lib\win32-x86」配下にある dll を利用します。
OS、PROCESSING、Tess4Jのdll は、同じ bit 数のもので揃えてください。
OS、PROCESSING、libtesseract3051.dll のどれか1つでも 32bit と 64bit が混在していると動作しないので注意が必要です。
また動作させるためには、あなたのPCに Microsoft Visual C++ 2015 Redistributable のランタイムがインストールされている必要があります。
インストールされていない場合は、以下の公式サイトからダウンロードしてインストールしてください。
パスと環境変数を整備する
最後にパスと環境変数を整備します。
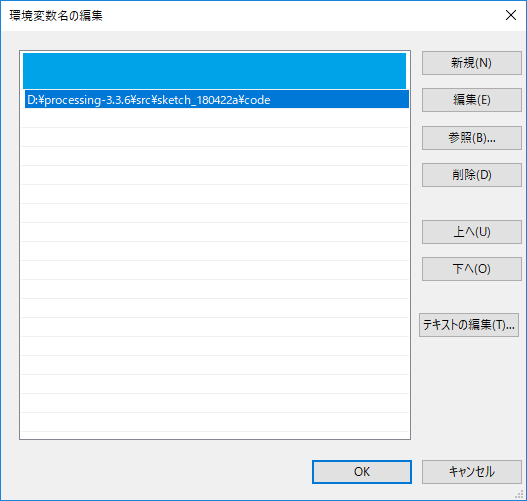
環境変数名:TESSDATA_PREFIX
値:上記で tessdata フォルダを複写した場所(D:\processing-3.3.6\src\sketch_180422a)を指定
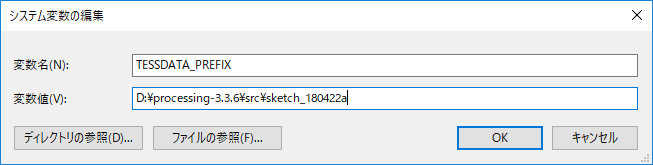
PATH:上記で libtesseract3051.dllを配置した場所(D:\processing-3.3.6\src\sketch_180422a\code)を追加
以上で準備は完了です。
【詳細】
全般的な注意
文字を読取る画像は、モノクロ2値画像で、かつ文字と文字以外の部分の明暗が明確に分かれている事が望ましいようです。
また認識させたい文字部分は、できるだけ明瞭で、クセの少ない大きな書体の文字が理想的です(・・・ま、当たり前ですね。笑)。
スマホのカメラで撮影した画像を与える場合は、事前に適切な画像加工を施しておく(対象画像をモノクロ化したり、文字のエッジを強調しておくなど)と、認識率が上がります。
特にランダムなノイズが混じった画像では、文字の認識速度が極端に遅くなり、精度が悪くなる傾向があります。また解析が困難な画像ではTesseractException例外が発生する事があります。
TesseractException例外が発生した場合は、何度もあきらめずに解析していると、そのうち例外で落ちること無く解析できるようになるようです。
読み取る文字の範囲が決まっている(数字だけなど)場合は、ホワイトリストで対象となる文字だけを指定すると、認識精度を高めることが可能です。
逆に認識してほしくない文字がある場合は、ブラックリストに指定する事で、その文字を除外して認識させることもできます。
以下は参考にさせて頂いたサイト様です。ありがとうございます。
- JProgramer tesseract-ocrをMacで使ってみた 様 (2022/05 Linkが見つかりません)
- Another Cul-de-sac 様
- プログラム の個人的なメモ 様
- 株式会社ライズウィル 様
インスタンスを作成する
インスタンスを作成ITesseract instance = new Tesseract();
instance : Tesseractオブジェクト
OCRを行うには、まずはインスタンスを作成します。
解析する言語を指定する
言語指定void instance . setLanguage(String language);
language : 言語指定。日本語なら “jpn”、英語は “eng”。ISO 639-3形式で指定する。
デフォルトは英語です。日本語を解析したい場合は “jpn” を指定します。
環境変数 TESSDATA_PREFIX で指定したパス配下のtessdataフォルダに、指定された言語ファイルが必要となります。デフォルトのまま使う場合でも、英語用のファイル(eng.traineddata)が必須となるので注意してください。
内部パラメータを指定する
パラメータを指定するvoid instance . TessBaseAPISetVariable(String name,String value);
name : 内部パラメータ名
value : 指定文字
nameに Tess4J の内部パラメータ名を与えます。以下の名前が利用できるようです。
tessedit_char_blacklist:ブラックリスト
tessedit_char_whitelist:ホワイトリスト
例えばホワイトリストで”0123456789″を指定すると、指定された文字(この場合は数字)のみを使って文字認識を試みるようになります。
当然ですが、漢字や平仮名は認識できなくなります。
|
1 2 3 4 |
//インスタンス作成 ITesseract instance = new Tesseract(); //数字と一部の四則演算記号のみ認識させる instance.setTessVariable("tessedit_char_whitelist","0123456789.×÷=-+"); |
またブラックリストで”0123456789″を指定すると、指定された文字(この場合は数字)を除外して、文字認識を試みるようになります。
ホワイトリストとブラックリストを上手に利用すれば、それなりに認識精度を向上させる事が可能でしょう。
文字を読み取る
OCRを実行するString result = instance . doOCR(java.io.File imageFile);
imageFile : 解析するイメージファイルの File オブジェクト
File で指定された画像ファイルから文字を読み取ります。読み取り結果は、横1ラインごとに改行で区切られた1つの文字列として、 result に戻されます。
解析で問題が発生すると TesseractException 例外が発生します。
 (画像URL:Frame Design 様)
(画像URL:Frame Design 様)
上記は解析例です。元画像をモノクロ化して解析画像に変換したのち、doOCR() させました。
解析結果は「t~プ~璽・ )(改行)名前‥よしひこ(改行)…」 という連続した文字列になっています。
赤枠が文字として認識された場所ですね。ライオンのエンブレムを文字と誤認しています。「:」が「‥」になっていたり、「1」が「 ]」 になっているのは御愛嬌でしょうか?(笑)。
OCRを実行するString result = instance . doOCR(BufferedImage bi);
bi: 解析するイメージファイルの java.awt.image.BufferedImage オブジェクト
解析するファイルに、BufferedImage型のオブジェクトを与えることも可能です。
事前に適切な加工を施した画像を与える場合は、加工後の画像をBufferedImage型のオブジェクトで与えるのが便利でしょう。
解析で問題が発生すると TesseractException 例外が発生します。
解析する
解析するList word = instance . getWords(BufferedImage bi, int pageIteratorLevel);
bi: 解析するイメージファイルの java.awt.image.BufferedImage オブジェクト
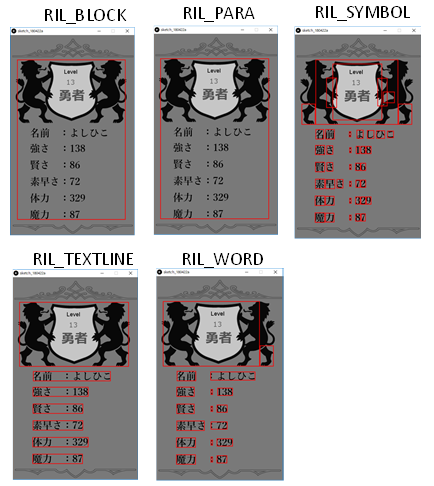
pageIteratorLevel : 解析レベル。TessPageIteratorLevel 型のenum値で、以下の何れかを指定する。
・RIL_BLOCK : ブロック
・RIL_PARA : 章立てされた文章
・RIL_SYMBOL : 単語で区切られた記号を含む文字
・RIL_TEXTLINE : 1行単位の文章
・RIL_WORD : 単語
BufferedImage で与えた画像を解析し、その結果を Word クラスのListとして返却します。
下記はTessPageIteratorLevelを変えて解析させた様子です。赤枠部分を文字と認識しています。各パラメータの違いが、なんとなくわかるのではないでしょうか?。
 (画像URL:Frame Design 様)
(画像URL:Frame Design 様)
Wordクラスからは、解析範囲(getBoundingBox)、信頼度(getConfidence)、解析文字(getText)の各種情報が得られます。
単にOCRできれば良いというのではなく、Tess4Jがどのように文字を解析しているのかを詳細に知りたい場合に役立ちます。
解析結果(文字列)を得るString text= word . getText() ;
text : 解析した文字列
word : getWords() で戻されたList内のWordインスタンス
doOCR() と同じく、OCRした文字列が戻されます。
解析信頼度を得るfloat conf = word . getConfidence() ;
conf : 信頼度。0 から 100 の値
word : getWords() で戻されたList内のWordインスタンス
解析範囲における信頼度(認識率)を%で戻します。数値が大きいほどパターンに良くマッチした事を示している・・・筈ですが、必ずしも「正確性(正しく認識できているか)」の指標にはならないようです(汗)。
解析範囲を得るRectangle rect = word . getBoundingBox() ;
rect : java.awt.Rectangle型の解析範囲を示す座標情報
word : getWords() で戻されたList内のWordインスタンス
Tess4Jが、画像のどの範囲を文字として認識したのかを示す座標情報が戻されてきます。
【関連記事】
サンプルプログラム
シンプルなOCR例:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 |
/** * PROCESSING OCR Sample * @auther MSLABO * @version 1.0 2018/04 */ import net.sourceforge.tess4j.*; import java.util.List; PImage target; void setup(){ size(400,640); target = loadImage("status.png"); //画像パスを指定する File image = new File(dataPath("") + "\\status.png"); //Tess4J インスタンス生成 ITesseract instance = new Tesseract(); //日本語解析を指定 instance.setLanguage("jpn"); try { //OCRする String result = instance.doOCR(image); //結果をテキストファイルに吐き出す String[] ocrStrings =result.split("\n", 0); saveStrings( dataPath("") + "\\kaiseki.txt", ocrStrings ); } catch( TesseractException ex ){ ex.printStackTrace(); } } void draw(){ background(target); } |
元画像を加工せずに、そのままOCRさせています。結果はテキストファイルに吐き出します。
「Level 13 勇者」と書かれた部分を誤認識していますね。また
「よ」→「ょ」
「:」→「‥」
「1」→「]」
「329」→「32g」
「魔力」→「厘力」
など細かな変換ミスも目立ちますが、思いの外がっばっています(笑)。
<出力サンプル>
 (画像URL:Frame Design 様)
(画像URL:Frame Design 様)
モノクロ化して解析する例:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 |
/** * PROCESSING OCR Sample * @auther MSLABO * @version 1.1 2018/04 */ import net.sourceforge.tess4j.*; import net.sourceforge.tess4j.ITessAPI.TessPageIteratorLevel; import net.sourceforge.tess4j.ITessAPI.TessOcrEngineMode; import java.awt.Image; import java.awt.Graphics; import java.awt.image.BufferedImage; import java.util.List; PImage target; List<Word> words; void setup(){ size(400,640); //画像を読み取り、モノクロ化する target = loadImage("status.png"); ImageMono(); //ImageをBufferedImageに変換する BufferedImage bimg = ChangeImage( target.getImage()); //Tess4J インスタンス生成 ITesseract instance = new Tesseract(); //日本語解析を指定 instance.setLanguage("jpn"); //必要な文字のみホワイトリストに指定する instance.setTessVariable("tessedit_char_whitelist", "0123456789:" + "Level勇者名前強さ賢さ素早さ体力魔力" + "よしひこ"); //1ライン単位に解析する words = instance.getWords(bimg, TessPageIteratorLevel.RIL_TEXTLINE); //結果をテキストファイルに吐き出す String result[] = new String[0]; for( Word w : words ){ result = append(result, w.getText()); } saveStrings( dataPath("") + "\\kaiseki.txt", result ); } //モノクロ化処理 void ImageMono( ){ //描画キャンパス生成 PGraphics pg = createGraphics(target.width,target.height); //描画開始 pg.beginDraw(); pg.background(target); //モノクロ化 pg.filter(GRAY); //描画終了 pg.endDraw(); target = pg; } //ImageをBufferedImageに変換する BufferedImage ChangeImage(Image imageFile){ //RGBの空BufferedImage作成 BufferedImage bimg = new BufferedImage( imageFile.getWidth(null), imageFile.getHeight(null), BufferedImage.TYPE_INT_RGB); //空BufferedImageにImageを描画 Graphics g = bimg.getGraphics(); g.drawImage(imageFile, 0, 0, null); g.dispose(); return bimg; } void draw(){ background(target); } |
カラー多値画像をモノクロ化してから解析しています。またホワイトリストを与えて、精度向上を狙いました。
本サンプルではPROCESSINGで画像加工していますが、あらかじめ画像加工ツールで処理しておけば、もう少し精度がよくなると思います。
<出力サンプル>
 (画像URL:Frame Design 様)
(画像URL:Frame Design 様)
本ページで利用しているアイコン画像は、下記サイト様より拝借しております。各画像の著作権は、それぞれのサイト様および作者にあります。